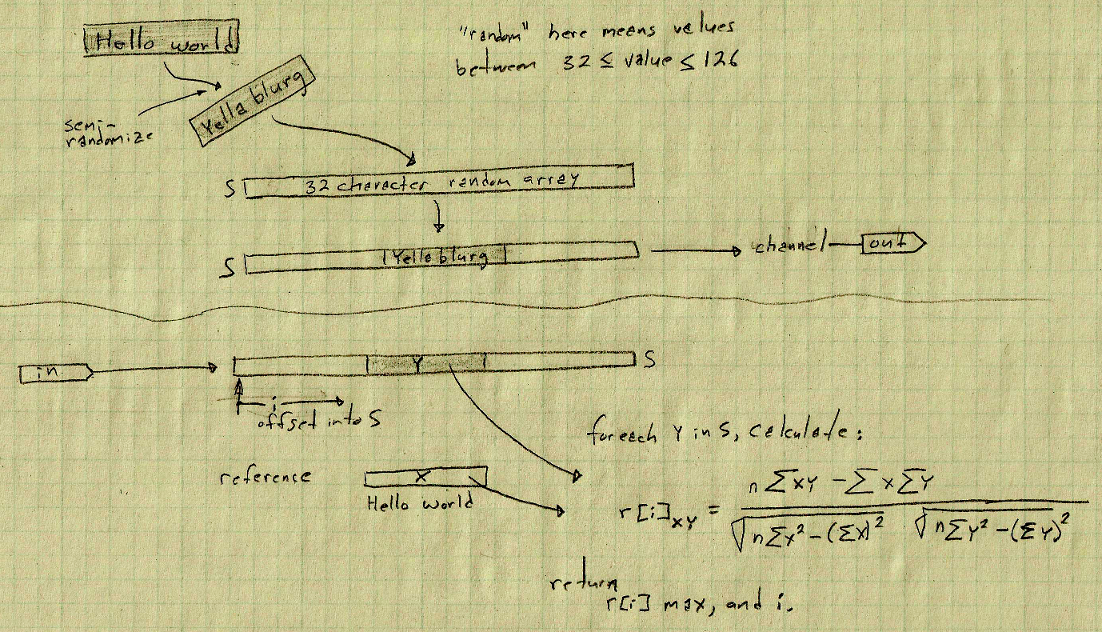
start | dir | Bytes | Description
-------+-------+-------+-------------------
addr00 | write | 1 | frameID
addr01 | write | 1 | CMMD
addr02 | write | 1 | arg0
addr03 | write | 1 | arg1
addr04 | write | 1 | RS Reference array/string Starting address
addr05 | write | 1 | RL Reference array/string Length
addr06 | write | 1 | SS S[] array/random string Starting address
addr07 | write | 1 | SL S[] array/random string Length
addr08 | --- | 1 | reserved
addr09 | read | 1 | status
addr10 | read | 1 | offset Returned value of the offset of maximum cc
addr11 | read | 1 | cc The maximum correlation coefficient in the form
(b.bbbbbbb, giving a range of 1 to 0 in steps of 2^-7, or 0.0078125)
addr12 | write | 11 | reference string bytes 0 - 0+RL
...
addr23 | write | 1 | unused
addr24 | write | 32 | S[] string bytes 0 - 0+SL
-------+-------+-------+-------------------
|
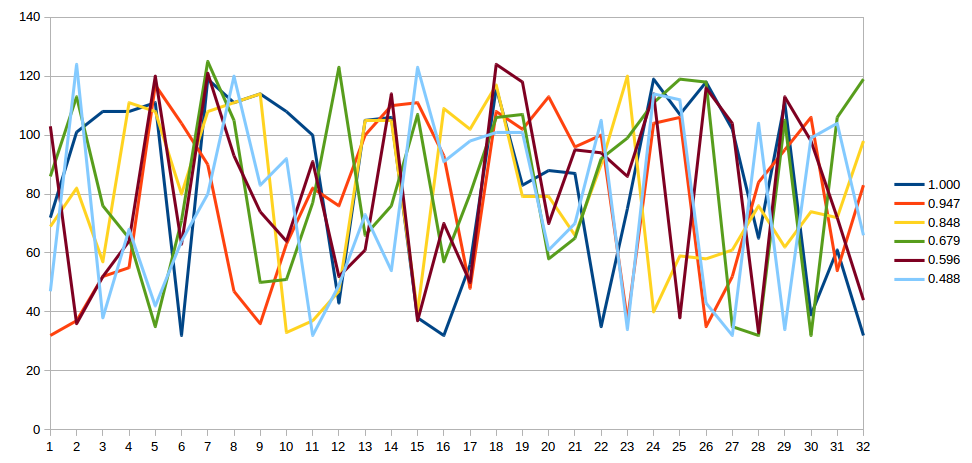
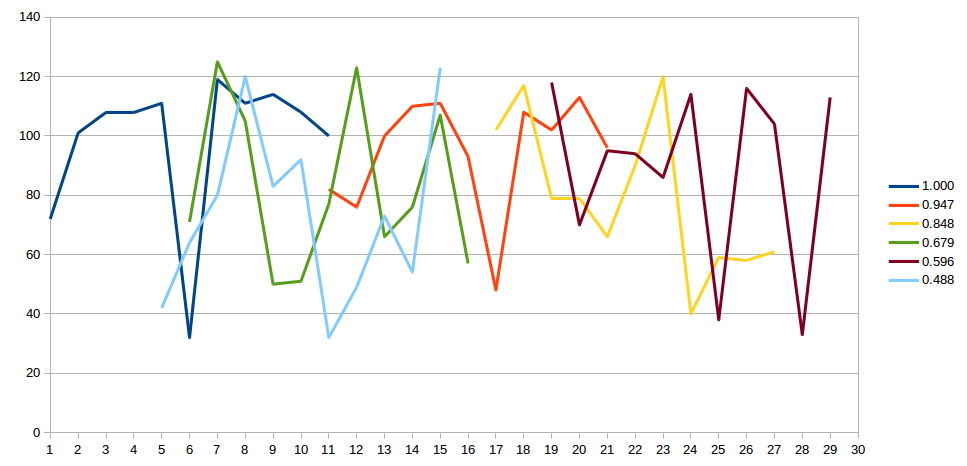
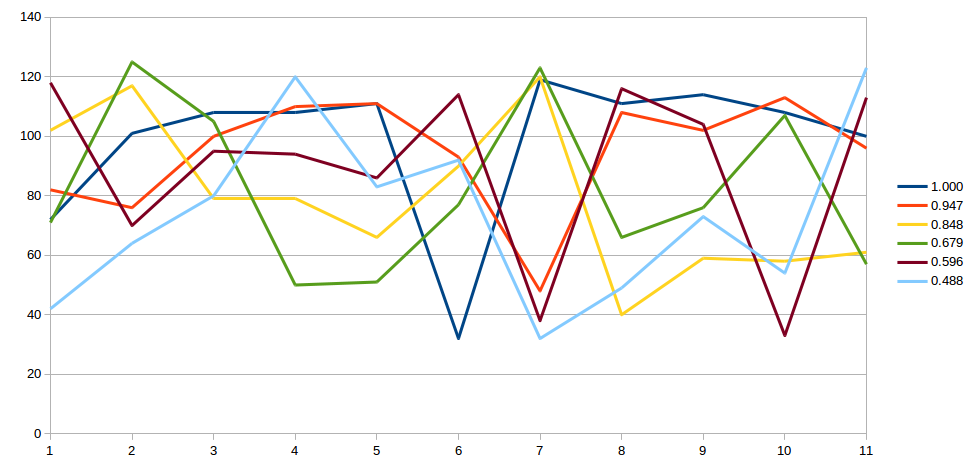
At the fragment starting at 0
--------------V
The string is Hello world+ij& 8tSXW#KwkvfAo'= <=-
Correlation coefficient w.r.t "Hello world" is is 1.000
At the fragment starting at 10
------------------------V
The string is U4f(7(8d*wFHkdm(neoZceRGb@]0 joQ
Correlation coefficient w.r.t "Hello world" is is 0.921
At the fragment starting at 17
------------------------------V
The string is ER9olPlor!%/ii(mfuOOBZx(;:=L>JHb
Correlation coefficient w.r.t "Hello world" is is 0.848
At the fragment starting at 6
--------------------V
The string is VqLA#G}i23M{BLk9Pjk:A\cowv# i jw
Correlation coefficient w.r.t "Hello world" is is 0.679
At the fragment starting at 19
--------------------------------V
The string is g$4@x?y]J@[4=r%F2|vF_^Vr&th!qbH,
Correlation coefficient w.r.t "Hello world" is is 0.596
At the fragment starting at 5
-------------------V
The string is /|&D*@PxS\ 1I6{[bee=Fi"rp+ h"chB
Correlation coefficient w.r.t "Hello world" is is 0.488
|
At the fragment starting at 10 ------------------------V The string is U4f(7(8d*wFHkdm(neoZceRGb@]0 joQ Correlation coefficient w.r.t "Hello world" is is 0.921 F + 2 = H H +29 = e k + 1 = l d + 8 = l m + 2 = o ( - 8 = n + 9 = w e +10 = o o + 3 = r Z +18 = l c + 1 = d |
HWSP block diagram: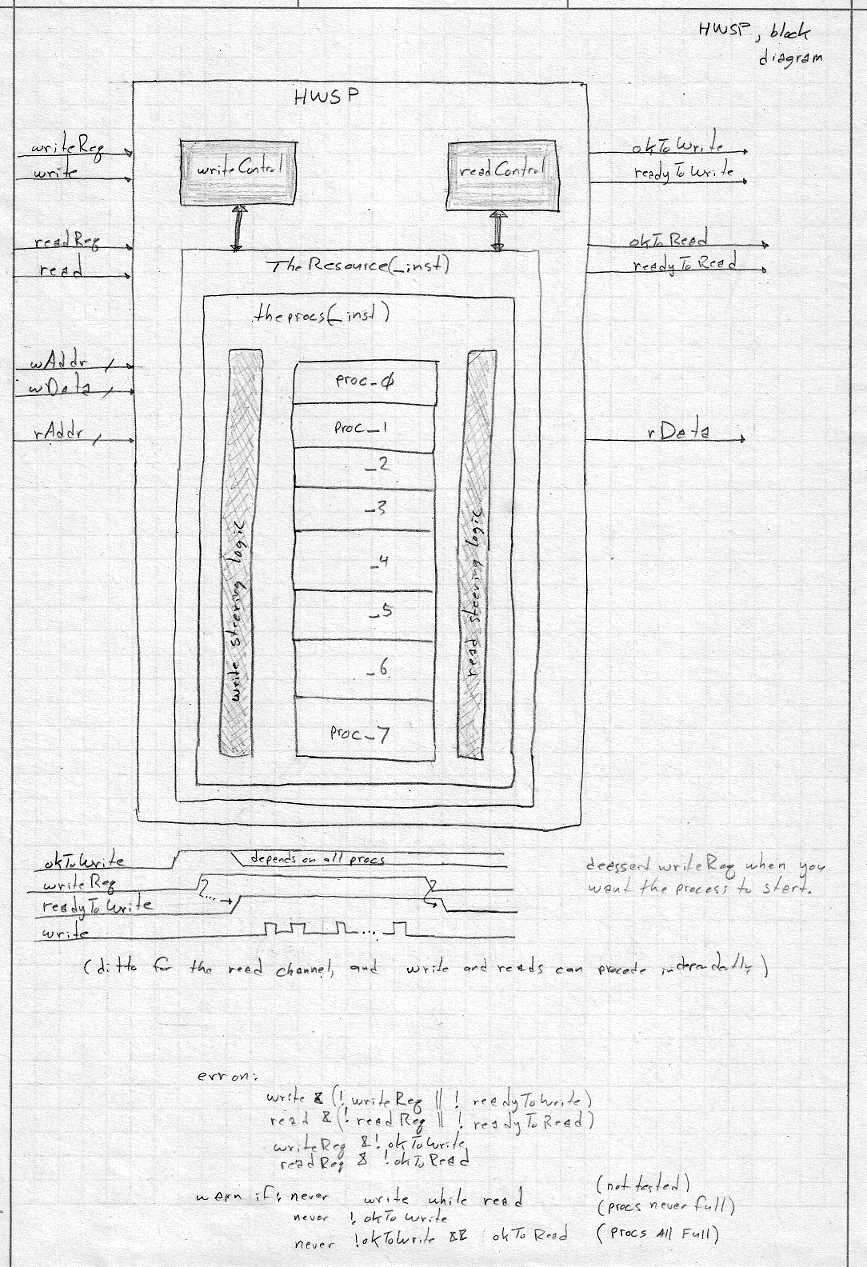
| theprocs block diagram: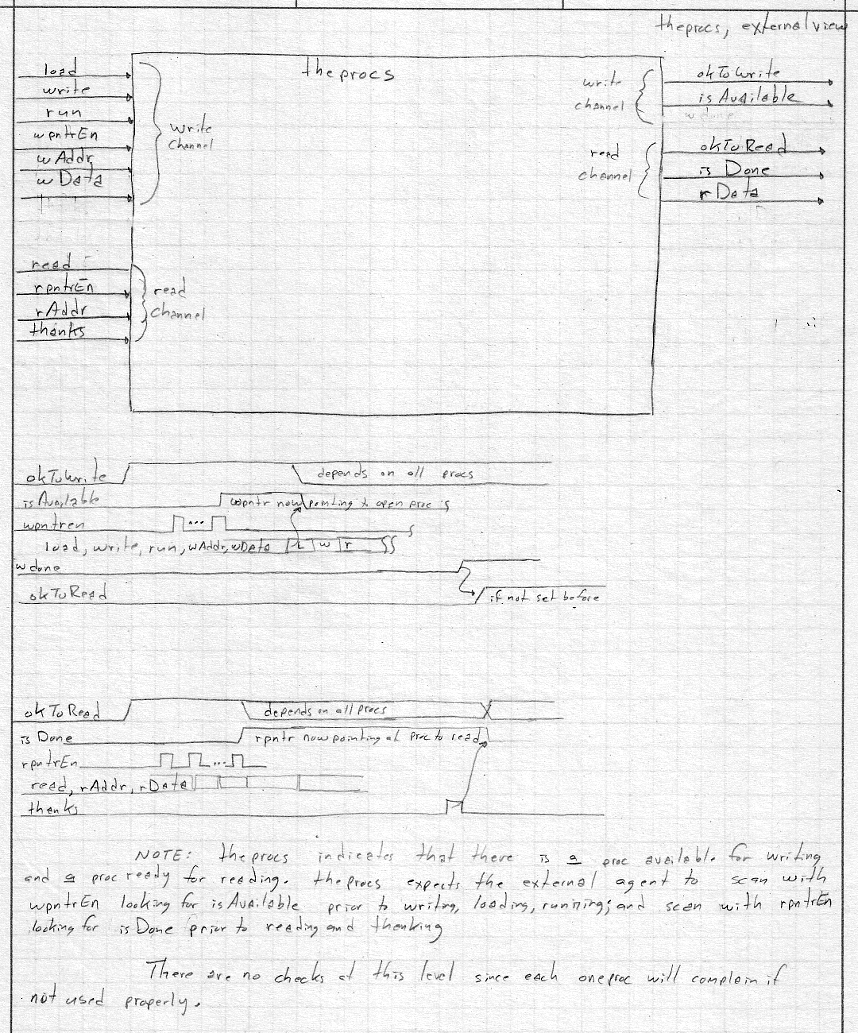
| theprocs internal diagram: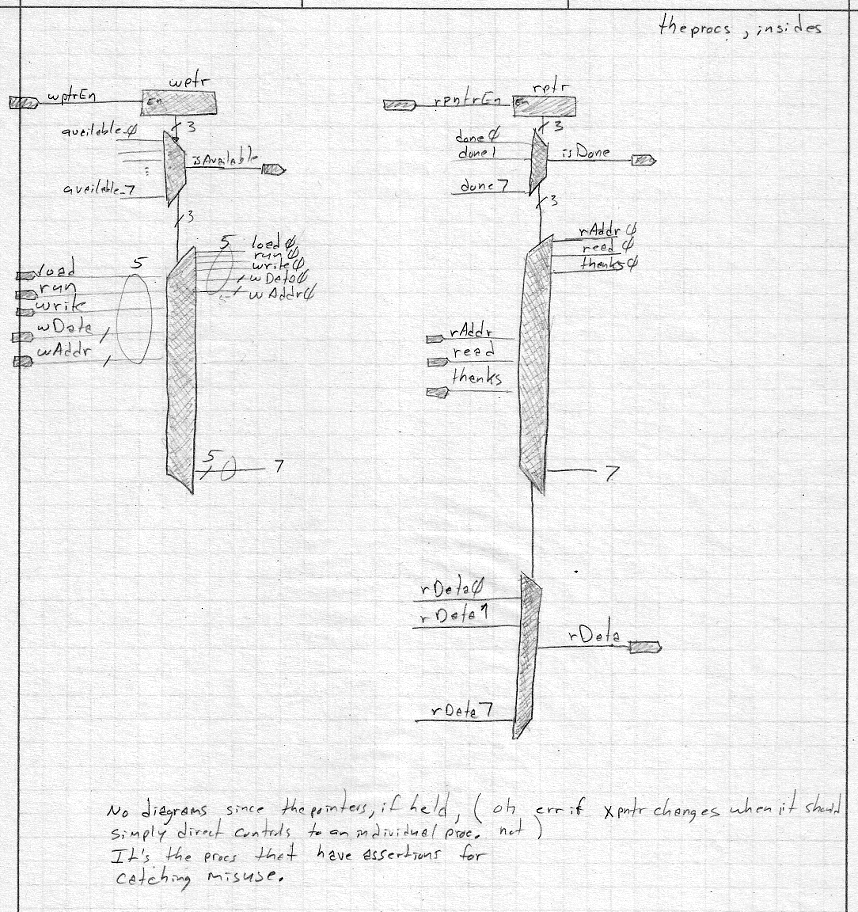
|
oneproc block diagram: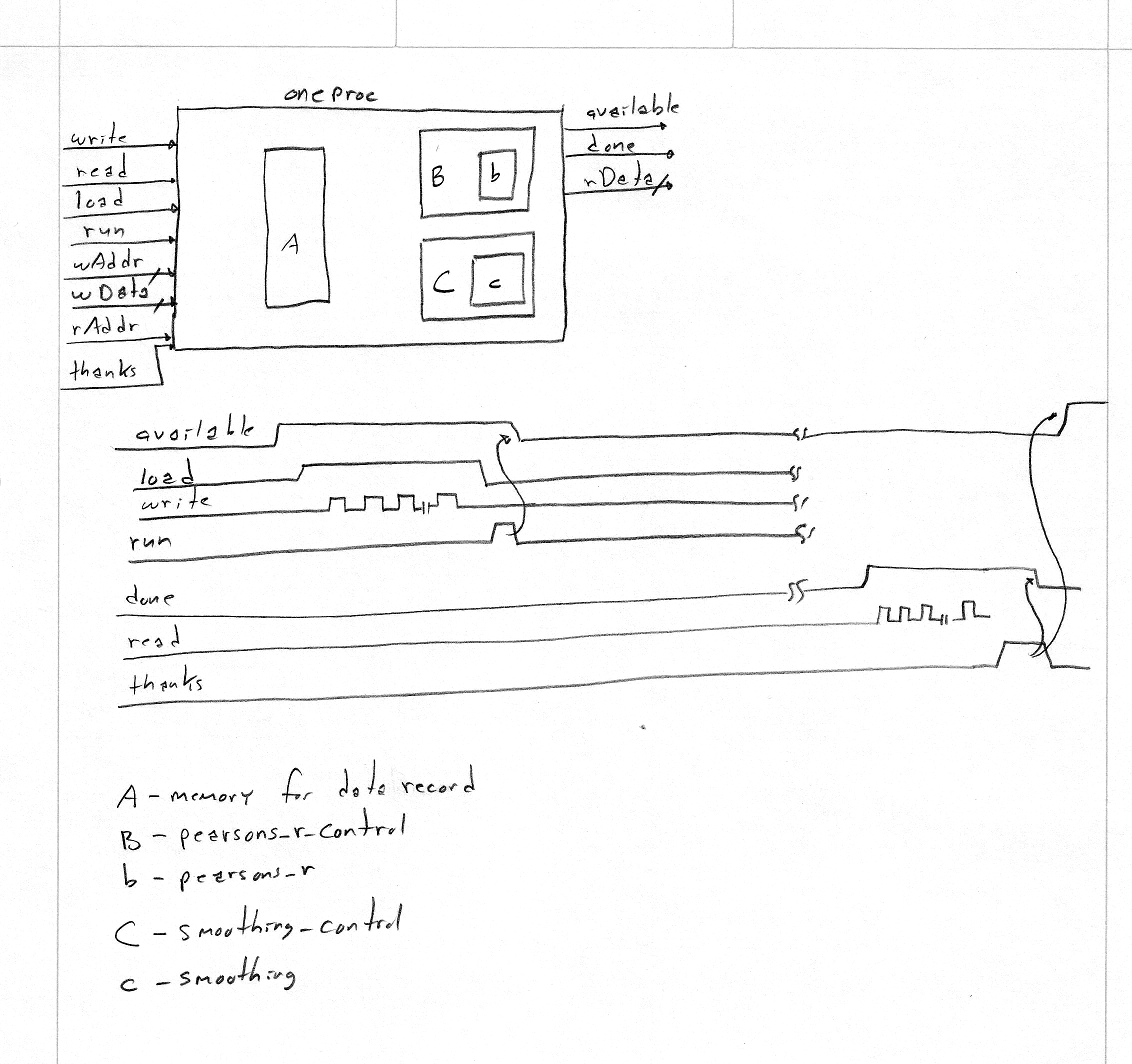
| oneproc internal diagram: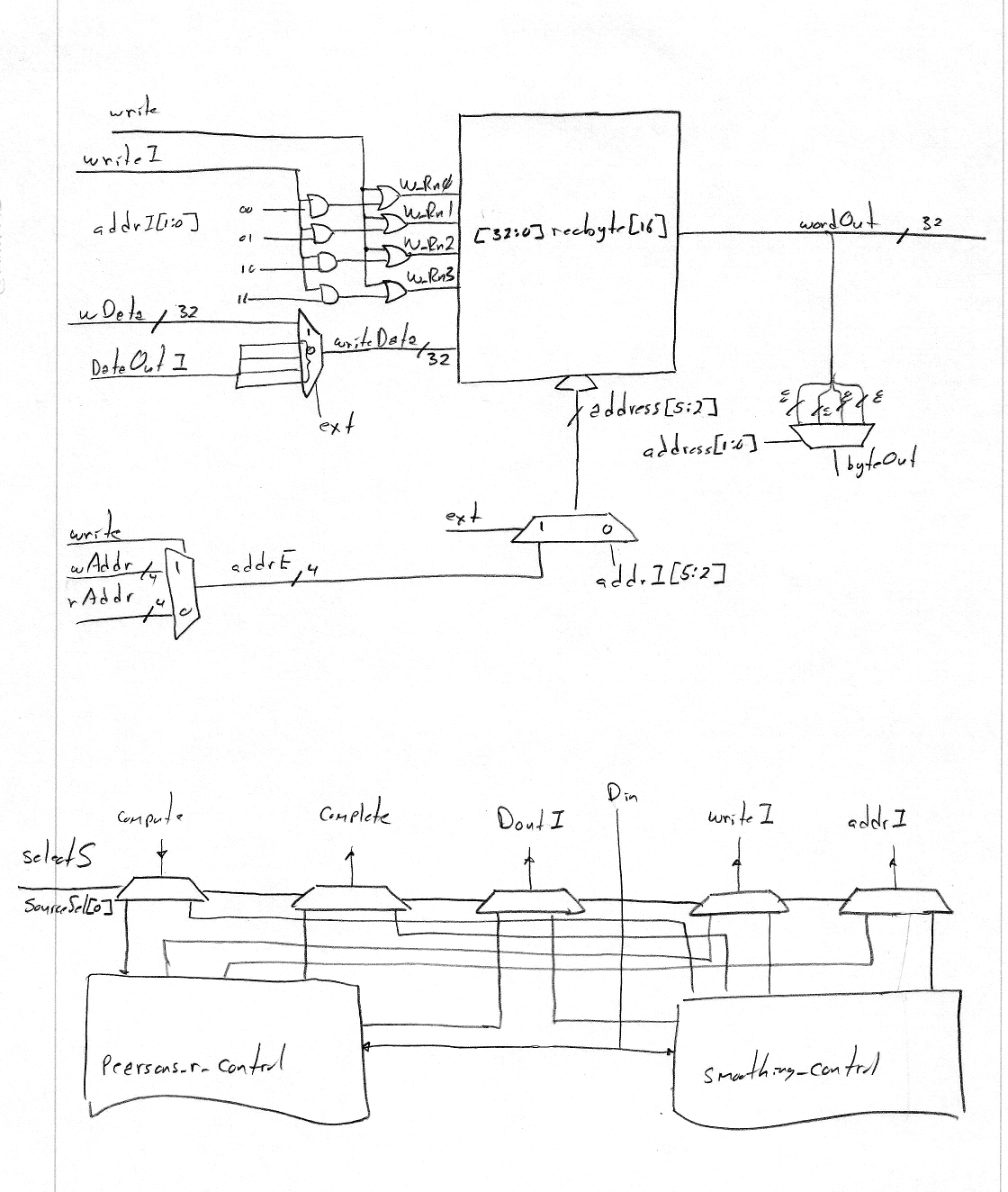
| |
pearsons_r internal diagram: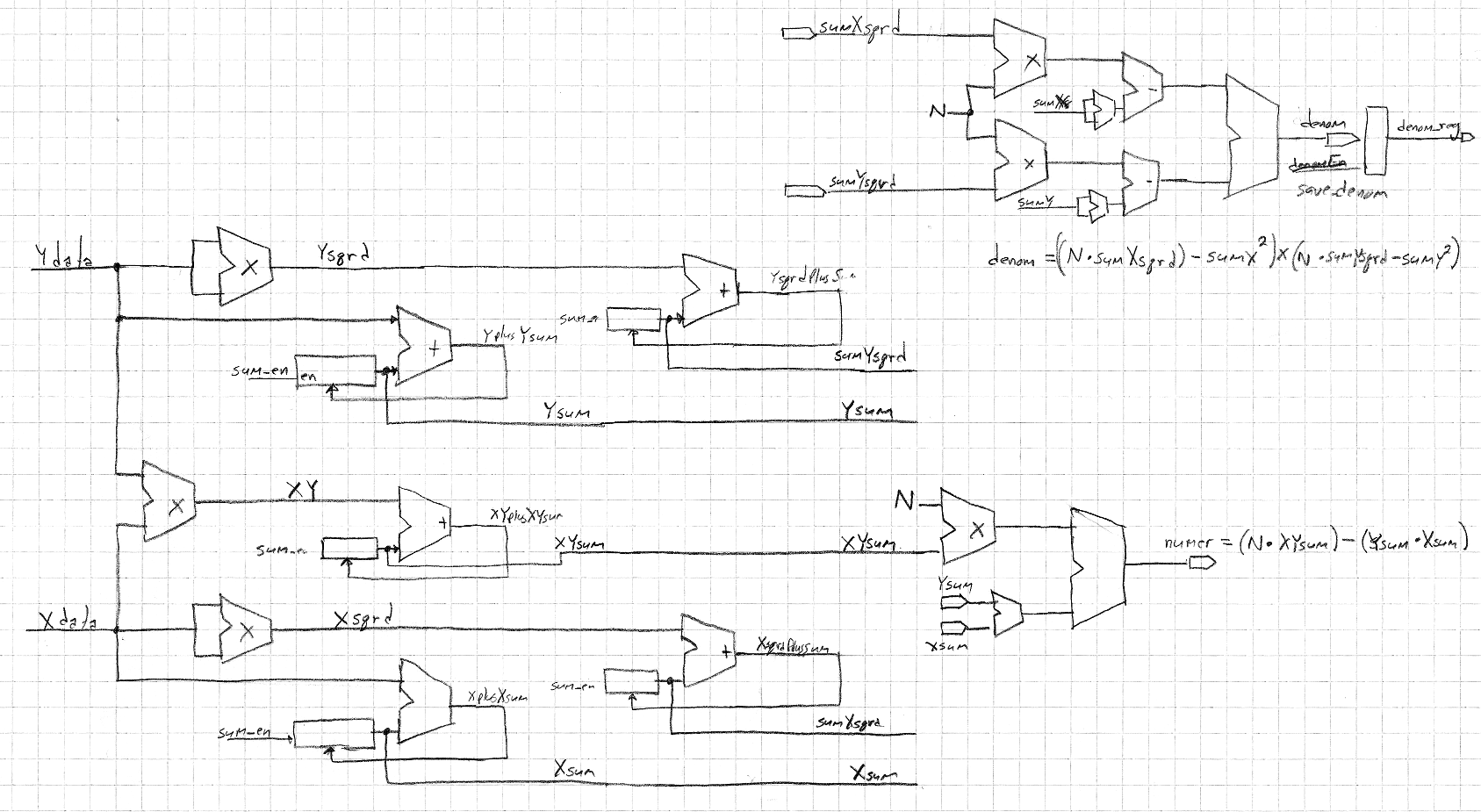
| pearsons_r_control internal diagram: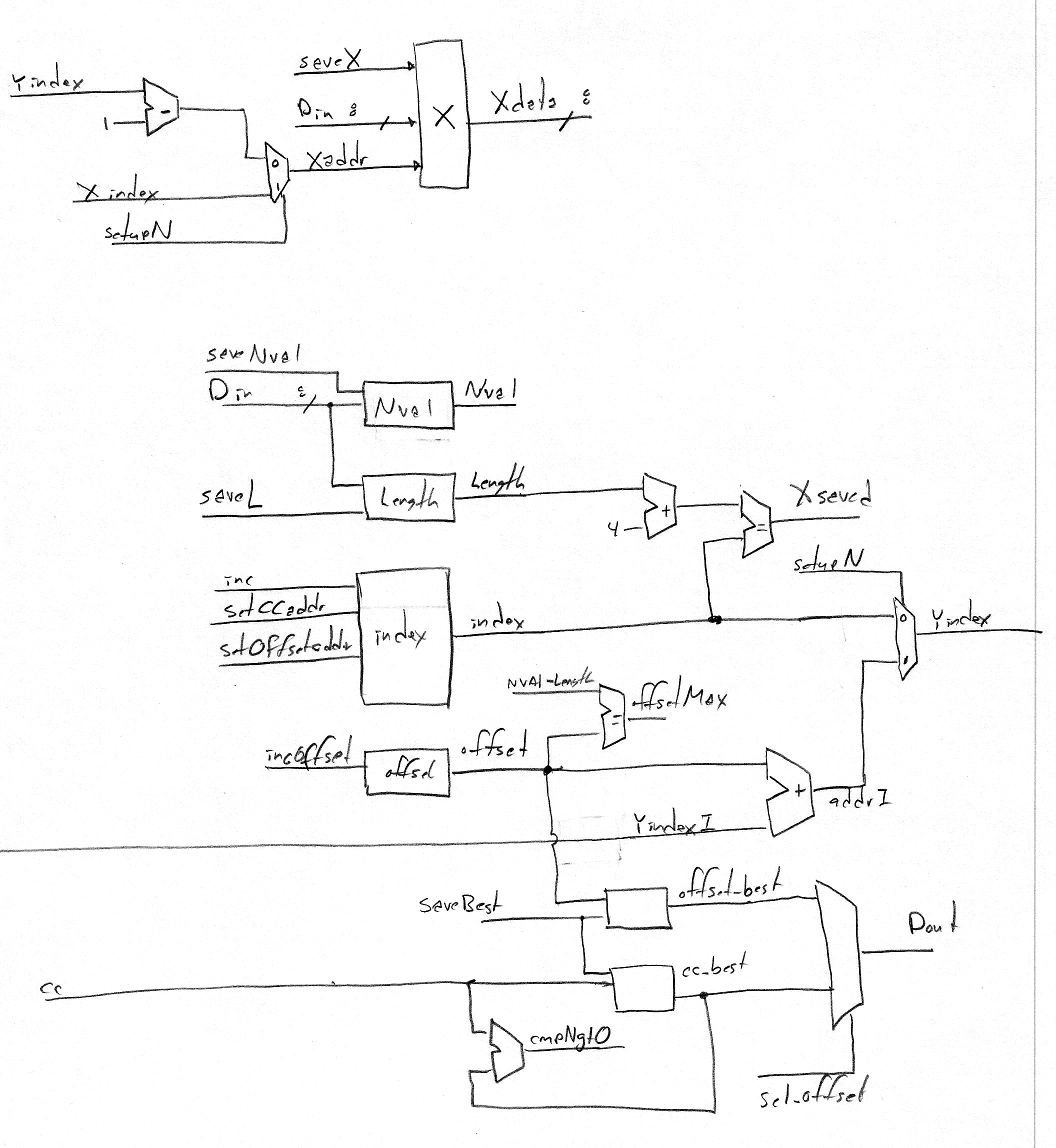
| |
smoothing_control internal diagram: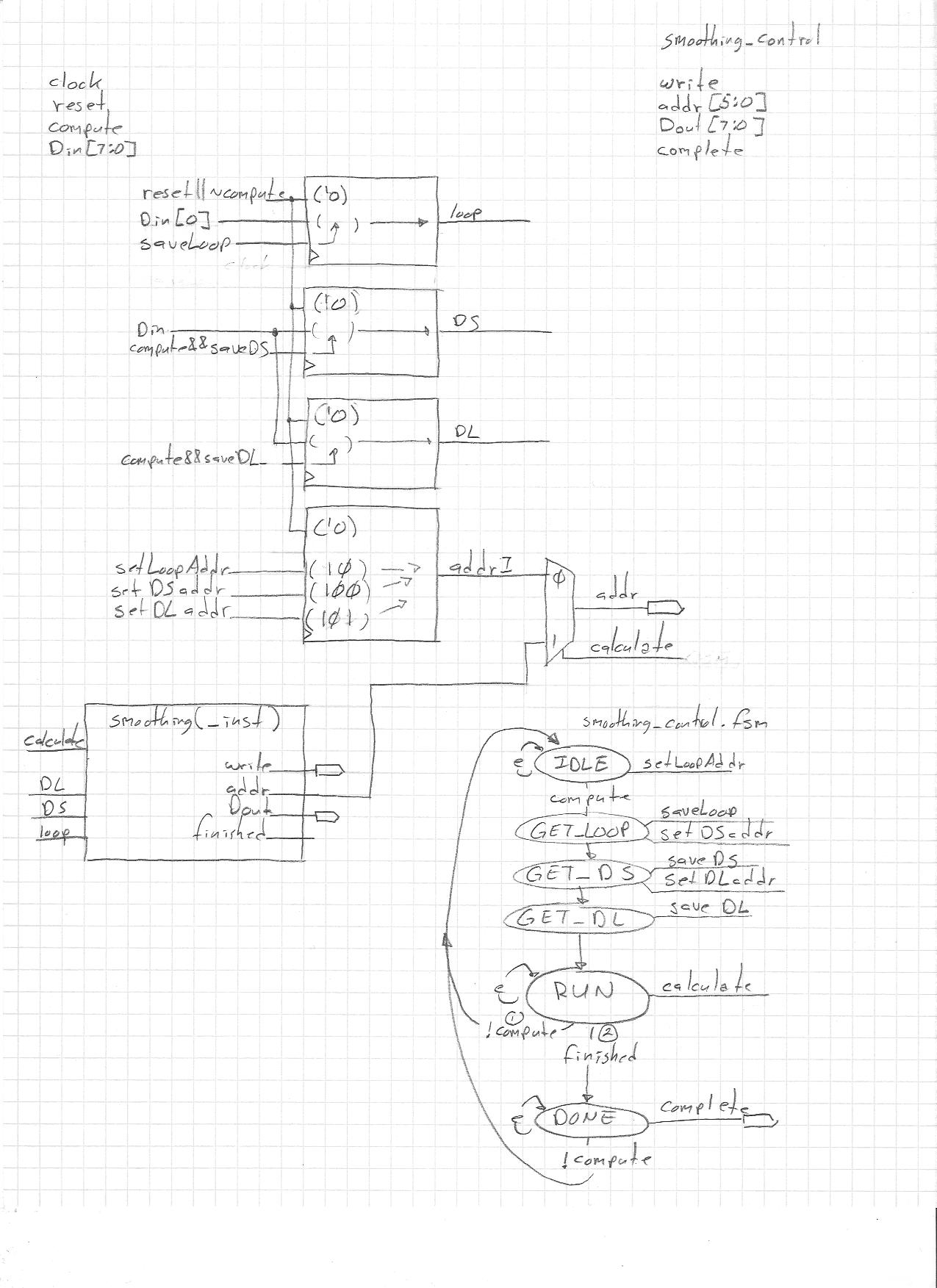
| smoothing internal diagram: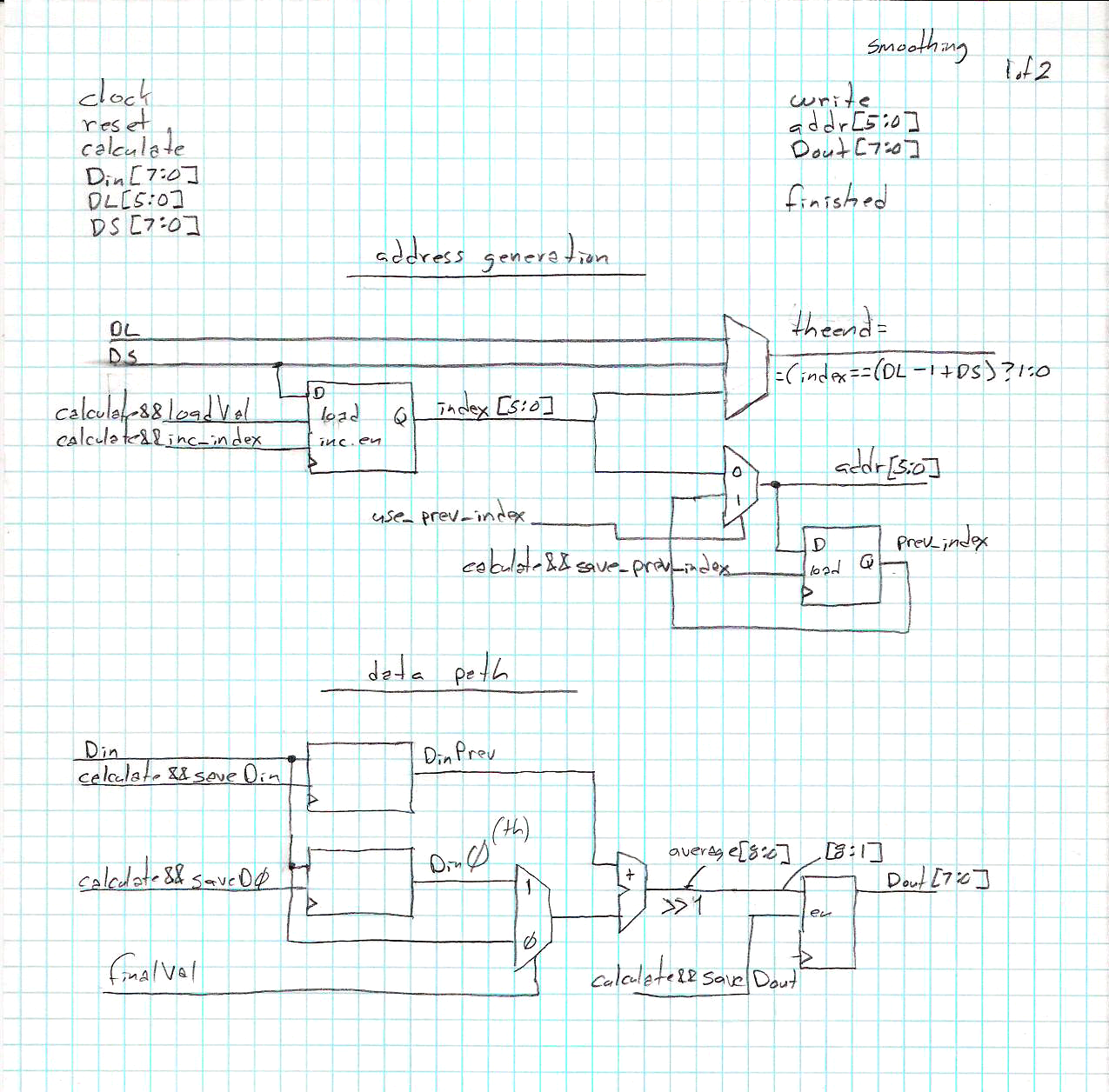
| smoothing FSM: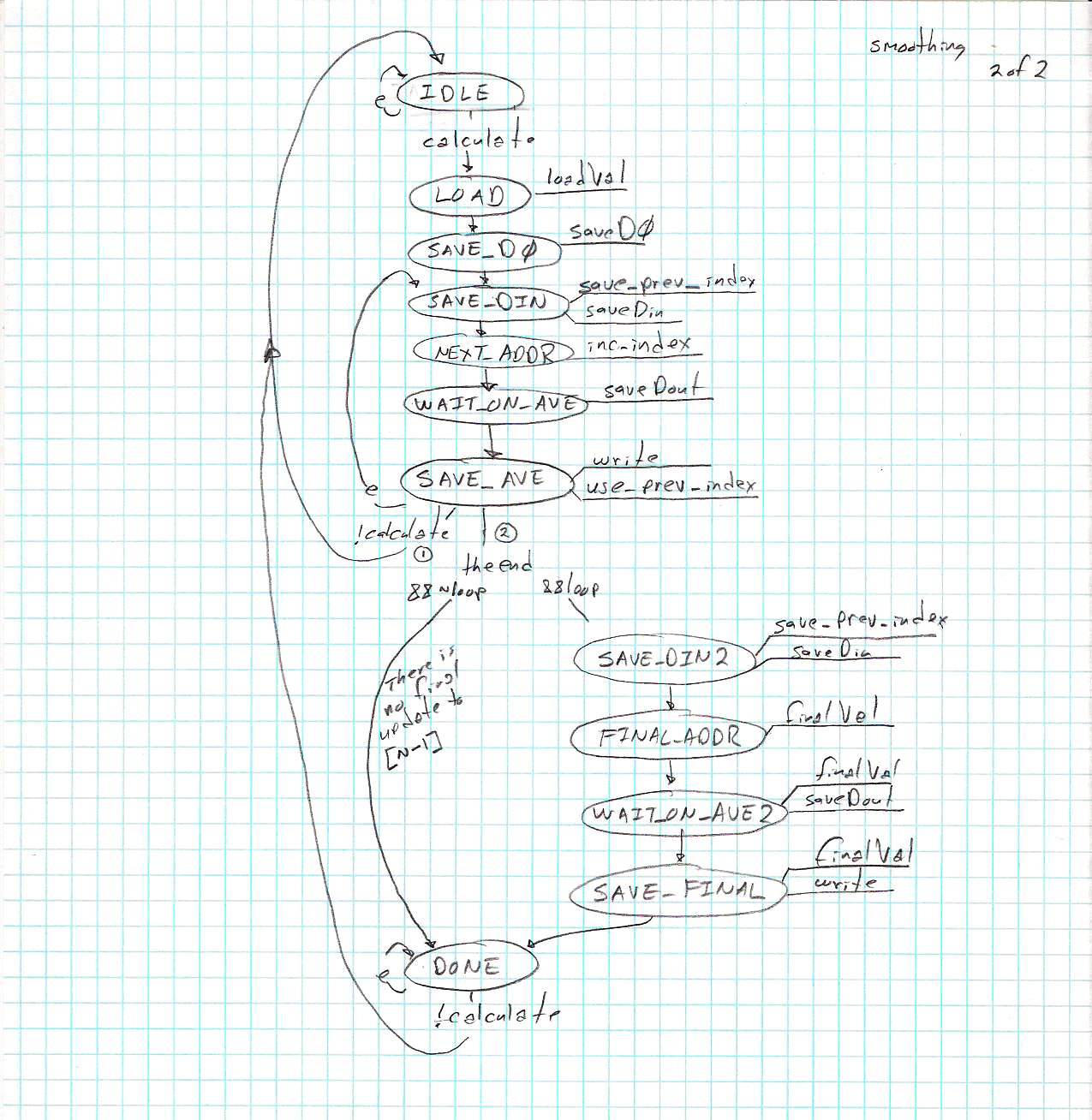
|
Given an N element array S, and a select signal to choose how to handle the final entry in the array, S0 = S[0] ; for (i=0; i < N-1; i++) S[i] = (S[i] + S[i+1])/2; S[N-1] = (select) ? S[N-1] : (S[N-1] + S[0])/2 ; |