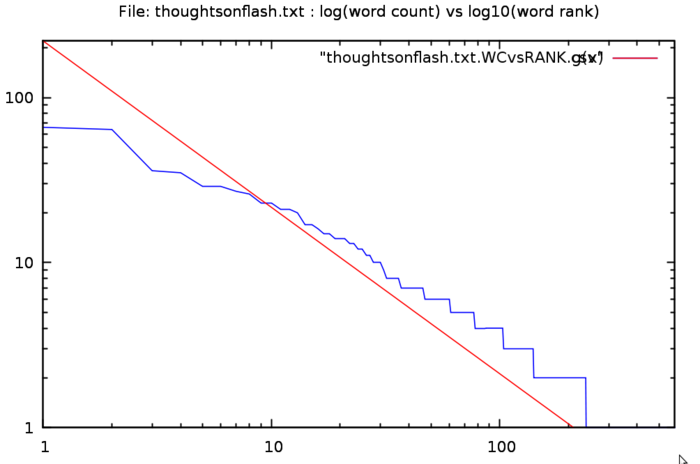
zwc -s -a -d -l -o outfiles -f thoughtsonflash.txt
The total word count is 1698
The unique words number 569
The ratio unique/total is 33.5100 %
The highest ranking 55 words make up 50.236 % of the total, OR
The number of words used once 336
The ratio (words used once)/total is 19.7880 %
The average of the ratios between frequencies is 1.0085
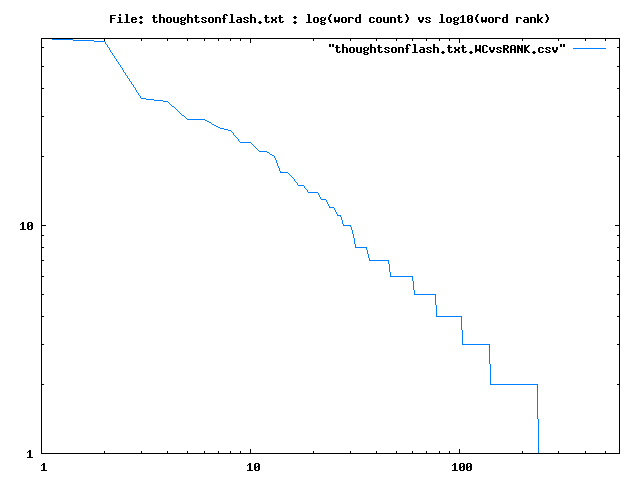
# ----------------------------------------- # word the # rank count word # ----------------------------------------- 1, 66, the 2, 64, and 3, 36, to 4, 35, flash 5, 29, is 6, 29, of 7, 27, for 8, 26, on 9, 23, we 10, 23, in 11, 21, a 12, 21, that 13, 20, adobe 14, 17, has 15, 17, they 16, 16, apple 17, 15, mobile 18, 15, devices 19, 14, our 20, 14, are 21, 14, it 22, 13, developers 23, 13, open 24, 12, platform 25, 12, web 26, 11, not 27, 11, their 28, 10, many 29, 10, all 30, 10, video 31, 9, third 32, 8, available 33, 8, party 34, 8, have 35, 8, by 36, 8, apps 37, 7, products 38, 7, with 39, 7, websites 40, 7, an 41, 7, from 42, 7, when 43, 7, but 44, 7, touch 45, 7, standards 46, 7, html5 47, 6, there 48, 6, iphones 49, 6, ipods 50, 6, ipads 51, 6, if 52, 6, using 53, 6, adobe's 54, 6, been 55, 6, this 56, 6, want 57, 6, any 58, 6, apple's 59, 6, will 60, 6, more 61, 5, uses 62, 5, h 63, 5, 264 64, 5, there's 65, 5, play 66, 5, be 67, 5, iphone 68, 5, ipad 69, 5, enhancements 70, 5, almost 71, 5, adopted 72, 5, adopt 73, 5, even 74, 5, best 75, 5, was 76, 5, create 77, 5, new 78, 4, browser 79, 4, webkit 80, 4, first 81, 4, half 82, 4, companies 83, 4, than 84, 4, other 85, 4, use 86, 4, proprietary 87, 4, support 88, 4, based 89, 4, software 90, 4, standard 91, 4, only 92, 4, cannot 93, 4, ipod 94, 4, example 95, 4, years 96, 4, now 97, 4, most 98, 4, can 99, 4, app 100, 4, games 101, 4, era 102, 4, pcs 103, 4, too 104, 3, system 105, 3, security 106, 3, 2009 107, 3, say 108, 3, second 109, 3, ship 110, 3, used 111, 3, google 112, 3, youtube 113, 3, battery 114, 3, videos 115, 3, without 116, 3, modern 117, 3, like 118, 3, need 119, 3, fact 120, 3, closed 121, 3, reason 122, 3, also 123, 3, experience 124, 3, one 125, 3, development 126, 3, cross 127, 3, platforms 128, 3, two 129, 3, fully 130, 3, mac 131, 3, them 132, 3, because 133, 3, users 134, 3, why 135, 3, power 136, 3, content 137, 3, store 138, 3, created 139, 3, as 140, 3, 2010 141, 2, were 142, 2, together 143, 2, around 144, 2, creative 145, 2, joint 146, 2, customers 147, 2, since 148, 2, controlled 149, 2, source 150, 2, widely 151, 2, its 152, 2, technology 153, 2, full 154, 2, times 155, 2, others 156, 2, true 157, 2, entertainment 158, 2, titles 159, 2, performance 160, 2, these 161, 2, don't 162, 2, reliability 163, 2, well 164, 2, device 165, 2, few 166, 2, said 167, 2, smartphone 168, 2, then 169, 2, long 170, 2, life 171, 2, much 172, 2, every 173, 2, vimeo 174, 2, netflix 175, 2, recently 176, 2, decoder 177, 2, chips 178, 2, must 179, 2, while 180, 2, hours 181, 2, browsers 182, 2, safari 183, 2, which 184, 2, up 185, 2, over 186, 2, mouse 187, 2, css 188, 2, javascript 189, 2, would 190, 2, rewritten 191, 2, doesn't 192, 2, important 193, 2, do 194, 2, allow 195, 2, run 196, 2, know 197, 2, enhancement 198, 2, at 199, 2, may 200, 2, access 201, 2, set 202, 2, features 203, 2, tool 204, 2, goal 205, 2, help 206, 2, write 207, 2, although 208, 2, 10 209, 2, major 210, 2, developer 211, 2, os 212, 2, x 213, 2, advanced 214, 2, world 215, 2, ever 216, 2, seen 217, 2, so 218, 2, wider 219, 2, customer 220, 2, continually 221, 2, mice 222, 2, business 223, 2, understand 224, 2, beyond 225, 2, low 226, 2, where 227, 2, offering 228, 2, no 229, 2, or 230, 2, 000 231, 2, necessary 232, 2, applications 233, 2, perhaps 234, 2, should 235, 2, great 236, 2, tools 237, 2, future 238, 2, less 239, 1, relationship 240, 1, met 241, 1, founders 242, 1, proverbial 243, 1, garage 244, 1, big 245, 1, adopting 246, 1, postscript 247, 1, language 248, 1, laserwriter 249, 1, printer 250, 1, invested 251, 1, owned 252, 1, 20 253, 1, company 254, 1, worked 255, 1, closely 256, 1, pioneer 257, 1, desktop 258, 1, publishing 259, 1, good 260, 1, golden 261, 1, grown 262, 1, apart 263, 1, went 264, 1, through 265, 1, near 266, 1, death 267, 1, drawn 268, 1, corporate 269, 1, market 270, 1, acrobat 271, 1, today 272, 1, still 273, 1, work 274, 1, serve 275, 1, buy 276, 1, suite 277, 1, interests 278, 1, i 279, 1, wanted 280, 1, jot 281, 1, down 282, 1, some 283, 1, thoughts 284, 1, critics 285, 1, better 286, 1, characterized 287, 1, decision 288, 1, being 289, 1, primarily 290, 1, driven 291, 1, protect 292, 1, reality 293, 1, issues 294, 1, claims 295, 1, opposite 296, 1, let 297, 1, me 298, 1, explain 299, 1, 100 300, 1, sole 301, 1, authority 302, 1, pricing 303, 1, etc 304, 1, does 305, 1, mean 306, 1, entirely 307, 1, definition 308, 1, though 309, 1, operating 310, 1, strongly 311, 1, believe 312, 1, pertaining 313, 1, rather 314, 1, high 315, 1, implementations 316, 1, lets 317, 1, graphics 318, 1, typography 319, 1, animations 320, 1, transitions 321, 1, relying 322, 1, plug 323, 1, ins 324, 1, completely 325, 1, committee 326, 1, member 327, 1, creates 328, 1, began 329, 1, small 330, 1, project 331, 1, complete 332, 1, rendering 333, 1, engine 334, 1, heart 335, 1, android's 336, 1, palm 337, 1, nokia 338, 1, rim 339, 1, blackberry 340, 1, announced 341, 1, microsoft's 342, 1, making 343, 1, repeatedly 344, 1, 75 345, 1, what 346, 1, format 347, 1, viewable 348, 1, estimated 349, 1, 40 350, 1, web's 351, 1, shines 352, 1, bundled 353, 1, discovery 354, 1, viewing 355, 1, add 356, 1, facebook 357, 1, abc 358, 1, cbs 359, 1, cnn 360, 1, msnbc 361, 1, fox 362, 1, news 363, 1, espn 364, 1, npr 365, 1, time 366, 1, york 367, 1, wall 368, 1, street 369, 1, journal 370, 1, sports 371, 1, illustrated 372, 1, people 373, 1, national 374, 1, geographic 375, 1, aren't 376, 1, missing 377, 1, another 378, 1, claim 379, 1, fortunately 380, 1, 50 381, 1, free 382, 1, symantec 383, 1, highlighted 384, 1, having 385, 1, worst 386, 1, records 387, 1, hand 388, 1, number 389, 1, macs 390, 1, crash 391, 1, working 392, 1, fix 393, 1, problems 394, 1, persisted 395, 1, several 396, 1, reduce 397, 1, adding 398, 1, addition 399, 1, performed 400, 1, routinely 401, 1, asked 402, 1, show 403, 1, us 404, 1, performing 405, 1, never 406, 1, publicly 407, 1, early 408, 1, think 409, 1, eventually 410, 1, we're 411, 1, glad 412, 1, didn't 413, 1, hold 414, 1, breath 415, 1, who 416, 1, knows 417, 1, how 418, 1, perform 419, 1, fourth 420, 1, achieve 421, 1, playing 422, 1, decode 423, 1, hardware 424, 1, decoding 425, 1, contain 426, 1, called 427, 1, industry 428, 1, blu 429, 1, ray 430, 1, dvd 431, 1, player 432, 1, added 433, 1, currently 434, 1, requires 435, 1, older 436, 1, generation 437, 1, implemented 438, 1, difference 439, 1, striking 440, 1, decoded 441, 1, 5 442, 1, before 443, 1, drained 444, 1, re 445, 1, encode 446, 1, offer 447, 1, perfectly 448, 1, google's 449, 1, chrome 450, 1, plugins 451, 1, whatsoever 452, 1, look 453, 1, fifth 454, 1, designed 455, 1, screens 456, 1, fingers 457, 1, rely 458, 1, rollovers 459, 1, pop 460, 1, menus 461, 1, elements 462, 1, arrow 463, 1, hovers 464, 1, specific 465, 1, spot 466, 1, revolutionary 467, 1, multi 468, 1, interface 469, 1, concept 470, 1, rollover 471, 1, rewrite 472, 1, technologies 473, 1, ran 474, 1, solve 475, 1, problem 476, 1, sixth 477, 1, besides 478, 1, technical 479, 1, drawbacks 480, 1, discussed 481, 1, downsides 482, 1, interactive 483, 1, wants 484, 1, painful 485, 1, letting 486, 1, layer 487, 1, come 488, 1, between 489, 1, ultimately 490, 1, results 491, 1, sub 492, 1, hinders 493, 1, progress 494, 1, grow 495, 1, dependent 496, 1, libraries 497, 1, take 498, 1, advantage 499, 1, chooses 500, 1, mercy 501, 1, deciding 502, 1, make 503, 1, becomes 504, 1, worse 505, 1, supplying 506, 1, unless 507, 1, supported 508, 1, hence 509, 1, lowest 510, 1, common 511, 1, denominator 512, 1, again 513, 1, accept 514, 1, outcome 515, 1, blocked 516, 1, innovations 517, 1, competitor's 518, 1, painfully 519, 1, slow 520, 1, shipping 521, 1, just 522, 1, cocoa 523, 1, weeks 524, 1, ago 525, 1, shipped 526, 1, cs5 527, 1, last 528, 1, motivation 529, 1, simple 530, 1, provide 531, 1, innovative 532, 1, stand 533, 1, directly 534, 1, shoulders 535, 1, enhance 536, 1, amazing 537, 1, powerful 538, 1, fun 539, 1, useful 540, 1, everyone 541, 1, wins 542, 1, sell 543, 1, reach 544, 1, audience 545, 1, base 546, 1, delighted 547, 1, broadest 548, 1, selection 549, 1, conclusions 550, 1, during 551, 1, pc 552, 1, successful 553, 1, push 554, 1, about 555, 1, interfaces 556, 1, areas 557, 1, falls 558, 1, short 559, 1, avalanche 560, 1, media 561, 1, outlets 562, 1, demonstrates 563, 1, longer 564, 1, watch 565, 1, consume 566, 1, kind 567, 1, 200 568, 1, proves 569, 1, isn't 570, 1, tens 571, 1, thousands 572, 1, graphically 573, 1, rich 574, 1, including 575, 1, such 576, 1, win 577, 1, focus 578, 1, creating 579, 1, criticizing 580, 1, leaving 581, 1, past 582, 1, behind 583, 1, steve 584, 1, jobs 585, 1, april